- 作業一(線性迴歸 複習)



===============================================



Model Selection
- R square


- AIC SBC
 |
| 書名:医学研究中的logistic回归分析及SAS实现和医学案例统计 |
- CP
 |
| 書名:introduction to linear regression analysis |
 |
| 書名:introduction to linear regression analysis |
一般來說,小CP值的模型會比較好。
- Forward
先建立只有一個解釋變數的模型,這個變數是所有變數中最顯著的,在放入剩餘變數中最顯著的變數,直到剩餘變數沒有顯著的。
先建立只有一個解釋變數的模型,這個變數是所有變數中最顯著的,在放入剩餘變數中最顯著的變數,直到剩餘變數沒有顯著的。
- Backward
先建立一個包含所有解釋變數的模型,在拿去最不顯著的變數,直到模型內變數都為顯著。
先建立一個包含所有解釋變數的模型,在拿去最不顯著的變數,直到模型內變數都為顯著。
- Stepwise
先建立只有一個解釋變數的模型,這個變數是所有變數中最顯著的,在放入剩餘變數中最顯著的變數。加入新變數時,如前一個變數變為不顯著則可替除。
先建立只有一個解釋變數的模型,這個變數是所有變數中最顯著的,在放入剩餘變數中最顯著的變數。加入新變數時,如前一個變數變為不顯著則可替除。
Comparison with the Maximal Model
- deviance判斷 logistic regression model 擬合程度。
 |
| 書名:introduction to linear regression analysis |
 |
| 書名:introduction to linear regression analysis |
飽和模型為估計值與觀測值完全相等,為不合理的一件事,但可以拿現有模型與飽和模型進行比較,來評估現有模型擬合數據的充分程度。
deviance服從卡方分配。
Diagnosis Methods
- Residual Analysis

書名:introduction to linear regression analysis
RESIDUALS

 |
| 書名:introduction to linear regression analysis |
RESIDUALS
STANDARDIZED RESIDUALS

大於3可能有問題

很大可能有問題

大於2可能有問題
殘差圖
如果殘差是獨立同分布,且服從N(0,sigma^2),那麼各點應該隨機的散佈如左上。
右上圖,殘差隨著解釋變數呈現二次形狀,可以嘗試在迴歸模型上添加二次項的變數。
左下圖,說明了殘差的變異數不是相等的,隨著解釋變數增大,變異數也增大。這種情況下可以嘗試將Y做轉換。
右下圖,說明了殘差不是獨立的。
 |
| 書名:SAS深入解析 |
COOK'S D
Di > 1 可能為影響點 或 Di > p/n 可能為影響點。
 |
| 書名:introduction to linear regression analysis |
 |
| 書名:introduction to linear regression analysis |
DFFITS DFBETAS
|DFBETASj,i| > 2 / sqrt(n) 可能為影響點。
|DFFITSi| > 2*sqrt(p/n) 可能為影響點。
 |
| 書名:introduction to linear regression analysis |
 |
| 書名:introduction to linear regression analysis |
covratio
COVRATIOi > 1+3p/n 或 COVRATIOi < 1-3p/n 可能為影響點。
 |
| 書名:introduction to linear regression analysis |
- Check for multicollinearity
r12表示x1與x2的相關係數,如趨近到1,則C會趨近到無限大。
var(b-hat) = C * MSres。
 |
| 書名:introduction to linear regression analysis |
 |
| 書名:introduction to linear regression analysis |
迴歸sas程式碼點此
=========================================================================
- 作業二(Wine Quality)
資料下載: Wine Quality Data Set
以直方圖與散佈圖顯示資料
macro程式碼點此
%mynormalcorr(mydata = red, y = quality,x = fixed_acidity
volatile_acidity
citric_acid
residual_sugar
chlorides
free_sulfur_dioxide
total_sulfur_dioxide
density
pH
sulphates
alcohol)
 |
| 雖然response為1到10的level,但並非每個level都有觀測值,所以無法進行multinomial logistic regression,只好當成連續變數。 |
 |











 |
| 變數間應該不會有共線性問題。 |
%myreg(data = red, y = Quality, x = fixed_acidity
volatile_acidity
citric_acid
residual_sugar
chlorides
free_sulfur_dioxide
total_sulfur_dioxide
density
pH
sulphates
alcohol,
option = selection = stepwise)

不管變數如何選擇,都會出現這個情形,可能是我把response當成連續的關係,但有的level沒有觀測值也不能做multinomial logistic regression。
或者response要進行轉換吧。
我使用stepwise方法進行變數選擇,但R平方只有0.35。
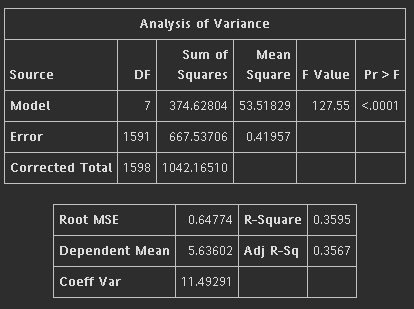 |
也有使用過其他方法但R平方都在0.2到0.3。

變數都為顯著,也沒共線性問題。
 |
chlorides free_sulfur_dioxide total_sulfur_dioxide 可以看出這三張圖是有問題的,所以我決定拿掉。 
但R平方還是一樣低
   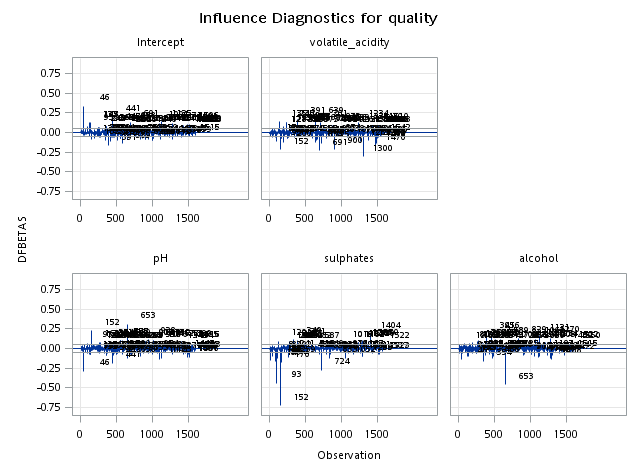  而且有非常多的觀測值可能為影響點。  我先以DFFITS為指標有超出的,以及outlier直接刪除試試看。
data test2_2;
merge test2 outlier;
if 1 <= _n_ <=3 then delete;
run;
data red2;
merge red test2_2;
if y3 ^= . then delete;
if RsByLevGroup = "Outlier" then delete;
keep Quality volatile_acidity pH sulphates alcohol;
run;
%myreg(data = red2, y = Quality, x = volatile_acidity pH sulphates alcohol)
|

R平方變成0.44,還是很低。
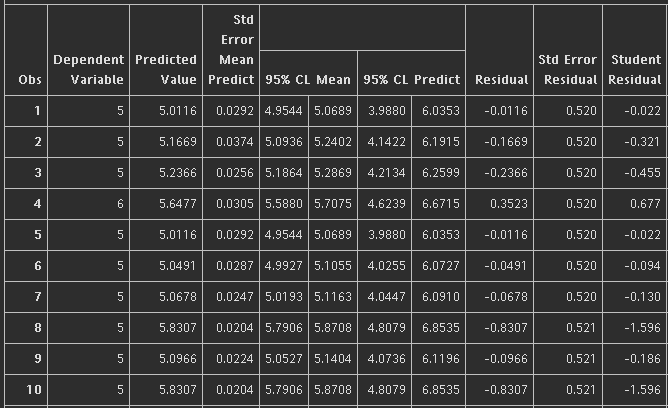






{kind=link}
0 意見:
張貼留言